When should you use this package?#
We have leveraged the experimental framework discussed by Pargent et al.[1] to analyze bayesian target encoding (BTE) and answer the following questions:
Marginal BTE: Is there lift from a staged approach:
Fit a submodel [*] that uses all non-categorical columns to predict the target.
Fit the encoder using the submodel output as the target.
Use the encoding and the raw input non-categorical data to fit the final model.
Encoder comparison#
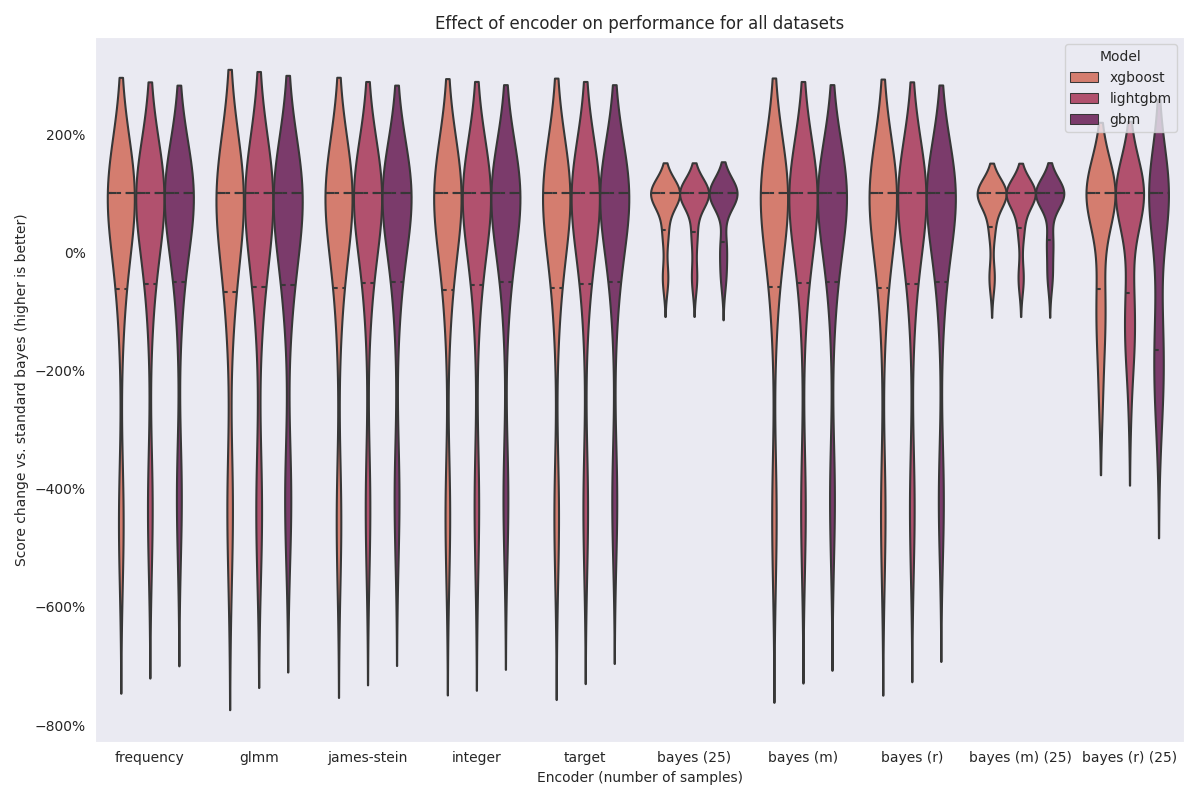
(m) indicates that the encoder used the “marginal” approach. (r) indicates
that the encoder uses the “residual” approach.#
In this experiment, we wanted to compare the standard bayesian target encoding to other popular encoding methodologies. We also wanted to test a “staged approach”, where we
fit a submodel that uses all non-categorical columns as features,
fit the encoder using either the submodel output (the “marginal” approach) or the residuals as the target, and
use the encoding and raw numeric features to fit the final model.
The idea here is that the categorical encoding can try to use the information not captured by numeric variables and produce a more useful encoding.
The aggregated visualization doesn’t show this well, but we have three takeaways from this experiment:
Non-sampled bayesian target encoding does not outperform other encoding methods,
Sample bayesian target encoding performs the best, and
marginal/residual encoding provides very incremental benefit at best.
Ensemble methodology[2]#
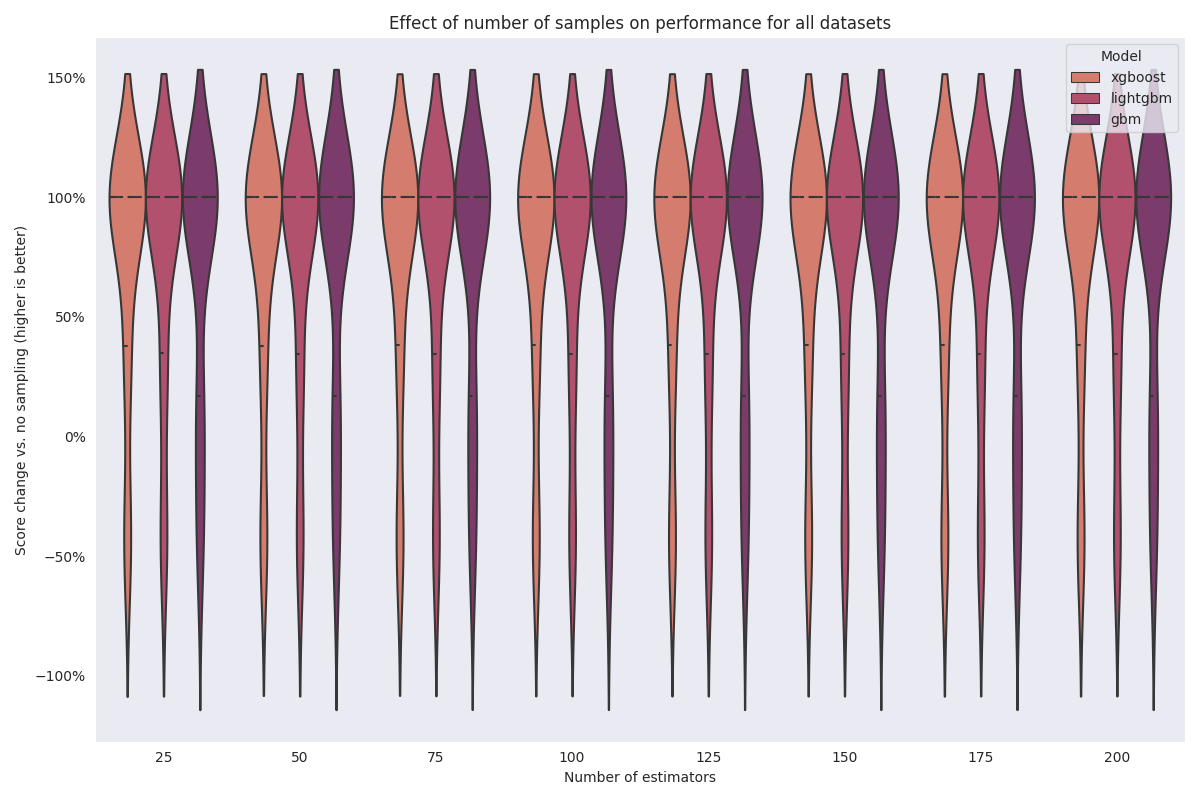
We wanted to answer the following questions:
How much does repeated sampling help?
How many samples do you need?
The short answer is that repeated sampling will almost definitely help with test performance. Only two datasets, churn and flight-delay-usa-dec-2017, saw decreases in test performance.
Surprisingly, only 25 samples are required to see an increase in performance.
Comparative encoding methodology#
When conducting these experiments, we’ll compare BTE to the following encoding methodologies. Suppose you have \(n\) training observations, with \(Y = (y_{1}, ..., y_{n})\) representing the target and categorical variable \(X_{1} = (x_{1}, ..., x_{n})\) with distinct values \(V = (v_{1}, ..., v_{l})\).
Pargent et al.[1] provide a description for each encoding methodology listed below.
Encoding |
Supervised? |
Implementation |
|---|---|---|
Frequency |
N |
|
Generalized Linear Mixed Model |
Y |
|
James-Stein |
Y |
|
Integer |
N |
|
Target |
Y |
|
Modeling algorithms#
The following modelling implementations will be tested:
Datasets#
Regression#
Below is a list of the regression datasets used for experimentation[1].
OpenML ID |
Dataset name |
|---|---|
Classification#
OpenML ID |
Dataset name |
|---|---|
Performance evaluation#
Pargent et al.[1] discussed a three-phase approach for creating a baseline assessment of model performance. We’ll adapt that here and use something slightly different. Baseline performance will be the average test score for a model fitted using the standard bayesian target encoder. We will repeat each experiment with 5 different random seeds for the train-test split.
Similar to Pargent et al.[1], we will use root mean squared error (RMSE) for
evaluating the performance of regression models and the area under the receiver
operating characteristic (AUROC) for classification problems. Both metrics are
available in scikit-learn[4] under the strings
neg_root_mean_squared_error and roc_auc, respectively.
Since we will not be doing any hyperparameter optimization, we will express the change in performance using a percentage increase in the stated metric.